Fisher kernel
In statistical classification, the Fisher kernel, named in honour of Sir Ronald Fisher, is a function that measures the similarity of two objects on the basis of sets of measurements for each object and a statistical model. In a classification procedure, the class for a new object (whose real class is unknown) can be estimated by minimising, across classes, an average of the Fisher kernel distance from the new object to each known member of the given class.
The Fisher kernel was introduced in 1998.[1] It combines the advantages of generative statistical models (like the hidden Markov model) and those of discriminative methods (like support vector machines):
- generative models can process data of variable length (adding or removing data is well-supported)
- discriminative methods can have flexible criteria and yield better results.
Contents |
Derivation
Fisher score
The Fisher kernel makes use of the Fisher score, defined as
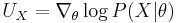
with θ being a set (vector) of parameters. The function taking θ to log P(X|θ) is the log-likelihood of the probabilistic model.
Fisher kernel
The Fisher kernel is defined as
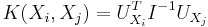
with I the Fisher information matrix.
Applications
Information retrieval
The Fisher kernel is the kernel for a generative probabilistic model. As such, it constitutes a bridge between generative and probabilistic models of documents.[2] Fisher kernels exist for numerous models, notably tf–idf,[3] Naive Bayes and probabilistic latent semantic analysis.
Image classification and retrieval
The Fisher kernel can also be applied to image representation for classification or retrieval problems. Currently, the most popular bag-of-visual-words representation suffers from sparsity and high dimensionality. The Fisher kernel can result in a compact and dense representation, which is more desirable for image classification[4] and retrieval[5] problems.
See also
Notes and references
- ^ Tommi Jaakkola and David Haussler (1998), Exploiting Generative Models in Discriminative Classifiers. In Advances in Neural Information Processing Systems 11, pages 487–493. MIT Press. ISBN 978-0-262-11245-1 PS, Citeseer
- ^ Cyril Goutte, Eric Gaussier, Nicola Cancedda, Hervé Dejean (2004))"Generative vs Discriminative Approaches to Entity Recognition from Label-Deficient Data" JADT 2004, 7èmes journées internationales analyse statistique des données textuelles, Louvain-la-Neuve, Belgium, 10-12 mars 2004
- ^ Deriving TF-IDF as a fisher kernel (2005) PDF [1]
- ^ Florent Perronnin and Christopher Dance (2007), “Fisher Kernels on Visual Vocabularies for Image Categorization”
- ^ Herve Jegou et al. (2010), “Aggregating local descriptors into a compact image representation”
- Nello Cristianini and John Shawe-Taylor. An Introduction to Support Vector Machines and other kernel-based learning methods. Cambridge University Press, 2000. ISBN 0-521-78019-5 ([2] SVM Book)